deepfacelab软件(附使用教程)
v25.03.2020- 软件大小:1.6GB
- 更新日期:2020-08-08
- 软件语言:简体中文
- 软件类别:图形图像
- 软件授权:免费版
- 软件官网:
- 适用平台:PC
软件介绍人气软件网友评论下载地址
随着AI换脸技术的在全世界的流行,很多国内视频作者多通过这种全新的技术进行趣味视频的制作,而小编为你准备了一个便捷的程序,它就是deepfacelab,这是一款强大的AI换脸软件,提供了智能换脸的功能,用户在导入素材以后,程序就会根据用户的导入,针对视频素材以及图片素材进行整理合并,从而为用户提供换脸的帮助,而且这个程序采用了全新的引擎制作,所以在整体素材的处理速度上比起同类软件,效率更高,而且它的技术更加成熟,会自动捕捉素材中的人脸,所以用户无需通过手动选择区域的方式来确认需要换脸的对象和目标,因此在操作难度上也比同类软件更低,那么你想要在各种有趣的素材中加入自己的精彩创意吗,那么就使用这个程序为视频任务进行换脸吧。

deepfacelab安装教程:
一、安装
1、在本站下载好压缩包后解压,找到并双击最新版的7z文件。
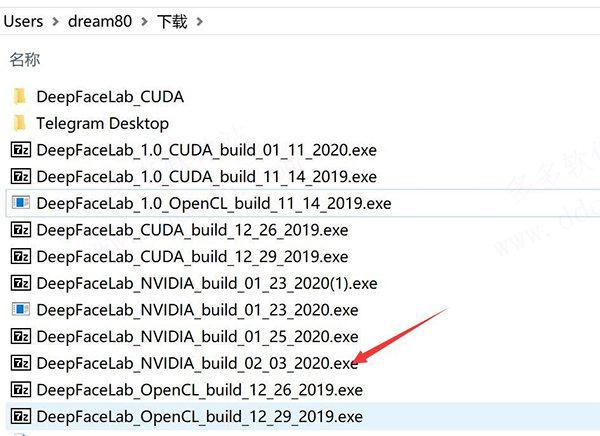
2、选择安装路径,建议放在C盘以外的磁盘,路径尽量短点不要包含特色字符。
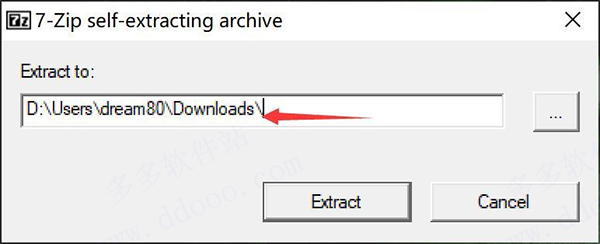
3、单击Extract开始解压软件。
注意:软件安装本质上只是解压而已,无需安装,就像很多绿色软件一样。如果QQ管家或者360报毒(都是流氓软件),添加信任放行即可。
依赖安装:依赖的意思就是使用这个软件之前必须要先安装的软件,DFL的唯一依赖就是显卡驱动。所以你只需要更新驱动即可使用此软件,CUDA和CUDNN不是必须的。
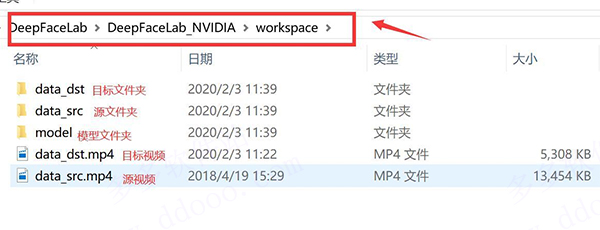
二、、目录
软件解压完成后会出现一个叫DeepFaceLab_NVIDIA的文件夹,里面有一个workspace,我们需要的文件都会在这里。这个文件夹下面有三个文件,两个视频,代表的意义如上图! 需要换自己的视频,只需要把这两个MP4换成自己的就好了。
软件运行过程中,在Data_dst 和data_src 中里面还会产生一个aligned的文件,里面会放置提取到的人脸图片,比较重要!
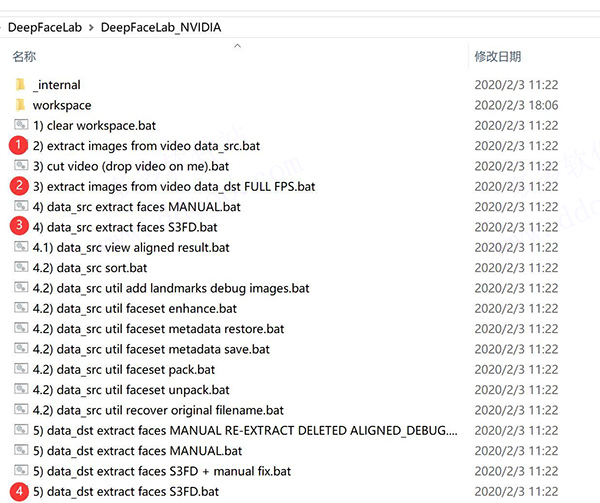
三、 流程介绍
进入软件目录后会发现很多以.bat结尾的文件,叫批处理文件。此类文件在window系统下可以直接双击运行,和exe没有两样了。大致步骤如上。
1、把视频转成图片
2、从图片中提取头像
3、用头像训练模型(模型相当于…..)
4、用训练好的模型实现图片换脸
5、把换好脸的图片合成视频!
使用教程
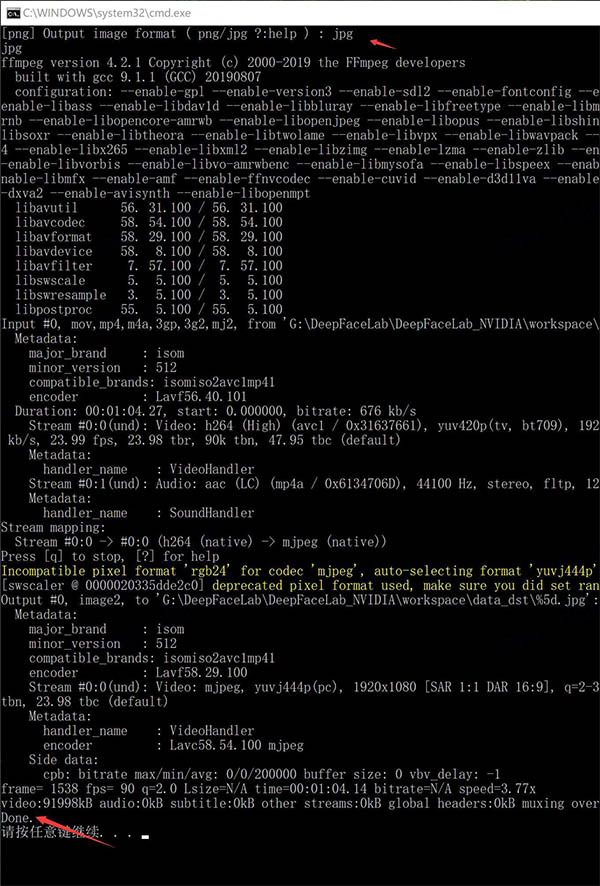
1、 首先把源视频拆分成图片
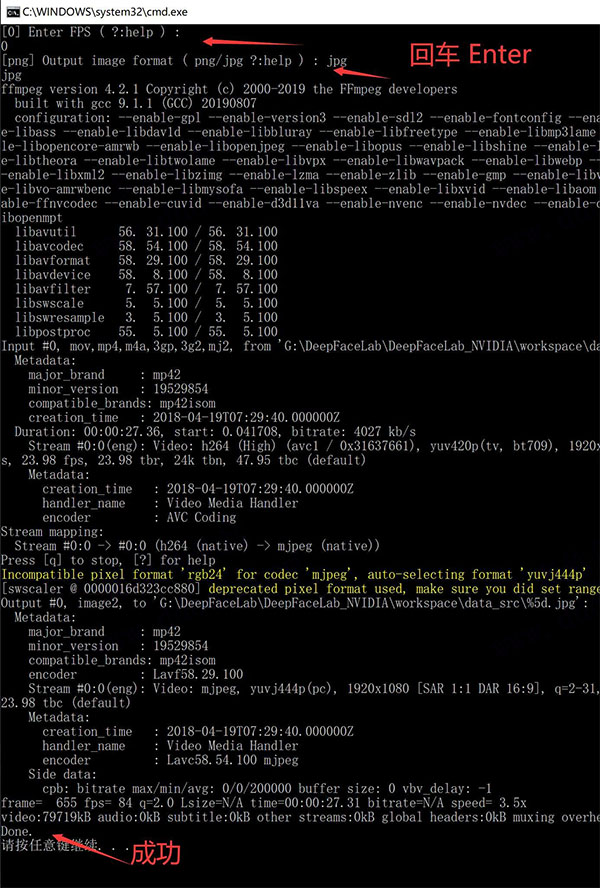
2、开头两个回车,等待,出现Done即表示处理成功。FPS :表示帧率,可以按回车默认,也可以输入一个数字。 Format代表图片格式,可以选JPG或者PNG,默认PNG。
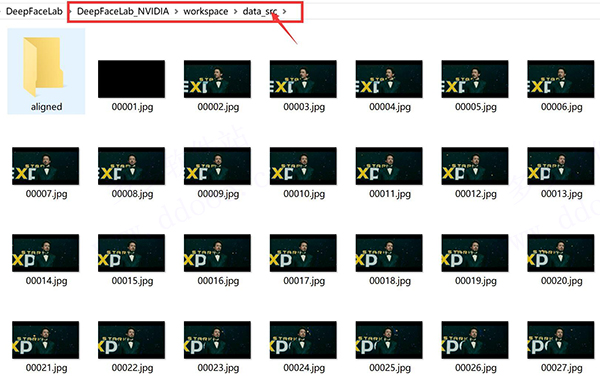
3、处理完成后,data_src文件夹下面会出现很多图片,这些图片就来自data_src.mp4视频。
4、一个回车,等待一段时间,看到Done表示结束。
处理完成后,data_dst文件夹下面会出现很多图片,这些图片就来自data_dst.mp4视频。)
5、两个回车,显示进度条,最后会显示发现的图片和提取到的人脸数量。 GPU index 是针对多卡用户,单卡用户直接回车。 Debug Image 一般不需要,默认回车即可。
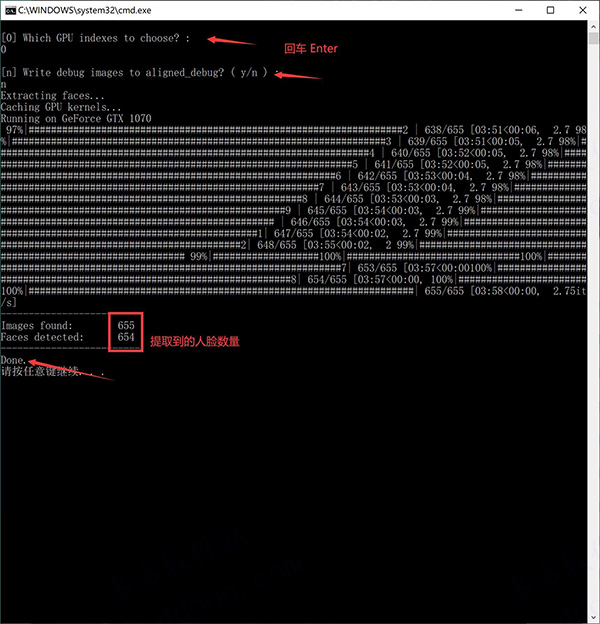
操作成功后,data_src/aligned 文件夹下面会出现唐尼的头像。

6、从目标图片中提取人脸
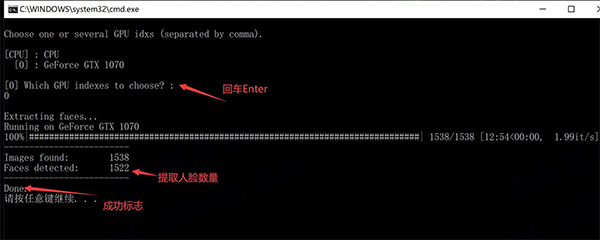
和上一步类似,只是少了一个参数Debug Image,其实是默认就启用了这个参数。
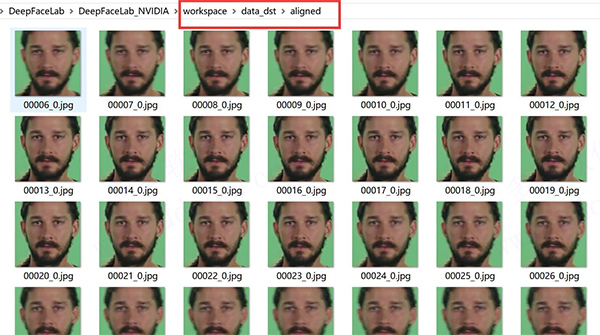
操作成功后,data_dst/aligned文件夹下会出现希亚·拉博夫的人头。在data_dst下面会出现一个aligned_debug文件夹。

软件特色
1、安装方便,环境依赖几乎为零,下载打包 app 解压即可运行(最大优势)
2、添加了很多新的模型
3、新架构,易于模型实验
4、人脸图片使用 JPG 保存,节省空间提高效率
5、CPU 模式,第 8 代 Intel 核心能够在 2 天内完成 H64 模型的训练。
6、全新的预览窗口,便于观察。
7、并行提取
8、并行转换
9、所有阶段都可以使用 DEBUG 选项
10、支持 MTCNN,DLIBCNN,S3FD 等多种提取器
11、支持手动提取,更精确的脸部区域,更好的结果。
软件功能
1、可单独使用,具有零依赖性,可与所有Windows版本的预备二进制文件(CUDA,OpenCL,ffmpeg等)一起使用。
2、新型号(H64,H128,DF,LIAEF128,SAE,恶棍)从原始的facewap模型扩展而来。
3、新架构,易于模型试验。
4、适用于2GB旧卡,如GT730。在18小时内使用2GB gtx850m笔记本电脑进行深度训练的示例
5、面部数据嵌入在png文件中(不再需要对齐文件)。
6、通过选择最佳GPU自动管理GPU。
7、新预览窗口
8、提取器和转换器并行。
9、为所有阶段添加了调试选项。
10、多种面部提取模式,包括S3FD,MTCNN,dlib或手动提取。
11、以16的增量训练任何分辨率。由于优化设置,使用NVIDIA卡轻松训练256。
deepfacelab配置要求
系统:Win7, Win10
显卡:GTX 1060以上效果较好,需要安装windows 版本的 VS2015,CUDA9.0和CuDNN7.0.5
优点:基于Faceswap定制的bat处理批版本,硬件要求低,2G显存就可以跑,支持手动截取人脸、集成所需要的素材和库文件,功能强大
缺点:复杂、处理批较多,脸部数据不能和其他deepfakes通用,需要重新截取
总结:适合有一定编程基础、追求效率高的用户
常见问题
1、人脸素材需要多少?
尽量不要少,因为它是有限的且需要被替换的素材,根据各软件的脸图筛选规则和网上大神的建议,总体来说,SRC脸图最好是大概700~3999的数量,像Deepfacelab的作者,他就认为1500张够了。对于SRC,各种角度、各种表情、各种光照下的内容越多越好,很接近的素材没有用,会增加训练负担。
2、手动对齐识别人脸模式如何使用?
回车键:应用当前选择区域并跳转到下一个未识别到人脸的帧
空格键:跳转到下一个未识别到人脸的帧
鼠标滚轮:识别区域框,上滚放大下滚缩小
逗号和句号(要把输入法切换到英文):上一帧下一帧
3、MODEL是个什么东西?
MODEL是根据各种线条或其他奇怪的数据经过人工智能呈现的随机产生的假数据,就像PS填充里的“智能识别”,你可以从 https://affinelayer.com/pixsrv/ 这个网站里体验一下什么叫MODEL造假
4、MODEL使用哪种算法好?
各有千秋,一般Deepfacelab使用H128就好了,其他算法可以看官方在GitHub上写的介绍:https://github.com/iperov/DeepFaceLab
5、Batch Size是什么?要设置多大?
Batch Size的意思大概就是一批训练多少个图片素材,一般设置为2的倍数。数字越大越需要更多显存,但是由于处理内容更多,迭代频率会降低。一般情况在Deepfacelab中,不需要手动设置,它会默认设置显卡适配的最大值。根据网上的内容和本人实际测试,在我们这种64和128尺寸换脸的操作中,越大越好,因为最合理的值目前远超所有民用显卡可承受的范围。
6、MODEL训练过,还可以再次换素材使用吗?
换DST素材:
可以!而且非常建议重复使用。
新建的MODEL大概10小时以上会有较好的结果,之后换其他DST素材,仅需0.5~3小时就会有很好的结果了,前提是SRC素材不能换人。
换SRC素材,那么就需要考虑一下了:
第一种方案:MODEL重复用,不管换DST还是换SRC,就是所有人脸的内容都会被放进MODEL进行训练,结果是训练很快,但是越杂乱的训练后越觉得导出不太像SRC的脸。
第二种方案:新建MODEL重新来(也就是专人专MODEL)这种操作请先把MODEL剪切出去并文件夹分类,这种操作可以合成比较像SRC的情况,但是每次要重新10小时会很累。
第三种方案:结合前两种,先把MODEL练出轮廓后,再复制出来,每个MODEL每个SRC脸专用就好了。
7、出现ValueError: No training data provided怎么办?
没有脸部数据,可能是你用其它软件截的脸,这是不行的,DFL仅支持自己截的脸。你可以将其它软件截的脸让DFL再截一遍就可以用了
8、出现ImportError: DLL load failed.
首先检查Microsoft Visual C++ distributed 2015 X64装了没有,如果装了就找度娘下载api-ms-win-downlevel-shlwapi-l1-1-0.dll(32位)和ieshims.dll复制到DFL的“_internal\python-3.6.8\Lib\site-packages\cv2”中,
9、为什么我换的脸是模糊的
运存过少,训练时间不够,src人脸过少,loss值太高(0.5以上都有点糊)以及”pixel_loss = True”(就是模糊的开关)都会导致这种情况,虽然512MB可以运行,但是结果肯定是不尽人意的,推荐运存2GB以上,训练时间一般10h以上,loss值推荐0.2左右。
10、为什么训练时loss值显示的是nan,而且马上就报错
这个我也不太清楚,可能是运存太低,解决办法就是“Use lightweight autoencoder? (Y / n,:? Help skip: n):”选择y(轻量编码器,速度快35%,输出结果目前看来差不多)。
11、为什么loss值降到一定就不降了
一般来说降到0.2左右训练就很成功了(一般需要10+h,Iter100000+,而我的电脑需要训练一个星期才能达到目标效果),但是也有特殊情况,降到1左右不再降的可能是脸差的太厉害了,比如讲一个男人的脸贴一个女人身上,当然也有可能是时间不够。
12、src需要多少个照片训练比较好
700~3000个左右,推荐1500个最好,太少的话即使loss降到0.1也是糊的,太多的话加重运算负担。
更新日志
deepfacelab软件 v25.03.2020更新说明
1、修复部分系统错误“Failed to get convolution algorithm”
2、修复部分系统错误“dll load failed”
3、修改模型下面的summary文件的格式,显示更多内容。
4、修改脸部遮罩,扩展眉毛部分区域,这个修改不影响Fan-x
5、转换遮罩:为底部区域添加遮罩渐变。
其他版本下载
- 查看详情 deepfacelab软件(附使用教程) 1.6GB 简体中文2020-08-08
- 查看详情 deepfake(ai智能换脸软件)中文免费版 214.55MB 简体中文2020-08-08
- 查看详情 LingoDeer(鹿老师说外语)免费版 39.18MB 简体中文2020-08-08
- 查看详情 DeepL Pro中文版 150.18 MB 简体中文2020-08-08
人气软件
-

xmind2025最新版 142MB
/简体中文 -

mindmanager2020中文版 231Mb
/简体中文 -

bartender10.1电脑版 607.12MB
/简体中文 -

abbyy finereader15电脑版 532.67Mb
/简体中文 -

fl studio20电脑版 663.58MB
/简体中文 -

ExpanDrive电脑版 144.34 MB
/简体中文 -

Ayoa Ultimate中文版 1.33kB
/简体中文 -

Altair ESAComp软件电脑版 50.28MB
/简体中文 -

DRmare Audio Converter电脑版 19.17 MB
/简体中文 -

MiniTool ShadowMaker数据恢复软电脑版 420.95MB
/简体中文
查看所有评论>>网友评论共0条
 Image Tuner专业版
Image Tuner专业版 PhotoStage Pro电脑版
PhotoStage Pro电脑版 Dynamo Cloth电脑版
Dynamo Cloth电脑版 CameraBag专业版
CameraBag专业版 Geometric Glovius电脑版
Geometric Glovius电脑版 CameraBag Pro汉化版
CameraBag Pro汉化版 Pixelmash电脑版
Pixelmash电脑版 CameraBag Photo电脑版
CameraBag Photo电脑版